
Maintaining high availability (HA) in a Docker Swarm cluster is crucial for production-grade deployments. In this blog, we’ll walk through the design and implementation of a high availability and automated recovery setup for Docker Swarm, hosted on a Proxmox datacenter. This setup ensures fault detection, rapid recovery of Swarm manager nodes, and minimal manual intervention—all with the help of custom scripting and basic monitoring tools.
Purpose
This post demonstrates how we configured Docker Swarm high availability across virtual machines in a Proxmox environment. You’ll learn how we:
- Monitor the health of the manager nodes
- Detect failures using a lightweight mechanism
- Automatically power on a standby VM and promote it to a Swarm manager
- Maintain Swarm quorum without manual intervention
We include detailed explanations and script samples, along with console outputs and commands.
Infrastructure Summary
2.1 Environment Details
- Virtualization Platform: Proxmox VE
- Cluster Type: Docker Swarm
- Cluster Configuration: 3 Manager Nodes + 1 Standby Manager Node
- Monitoring Node: Separate VM (IP: 10.1.1.66)
- Swarm Health Check: Node Exporter /metrics endpoint (port 9100)
2.2 Node List
Node Name | VM ID | Role | IP Address |
Node 1 | 106 | Swarm Manager | 10.1.1.61 |
Node 2 | 107 | Swarm Manager | 10.1.1.62 |
Node 3 | 108 | Swarm Manager | 10.1.1.60 |
Node 4 | 109 | Standby Manager | 10.1.1.63 |

3. Monitoring & Auto-Recovery Process
A cron job, scheduled to run every minute on a dedicated monitoring VM (10.1.1.66), executes a custom Bash script that checks the health of all Swarm manager nodes.
The logic is simple but effective:
- Query Node Exporter metrics on port 9100 for each manager.
- If any manager is unreachable, the script:
- Powers on the standby VM (VM 109) using Proxmox CLI via SSH.
- Waits for SSH availability.
- Joins the standby node to the Docker Swarm.
- Promotes it to a manager using a healthy node.
- Powers on the standby VM (VM 109) using Proxmox CLI via SSH.
This approach ensures self-healing of the Swarm manager quorum with zero manual step
4. Node Health Check Script
The monitoring script is designed to check each manager node’s availability using its Node Exporter metrics endpoint.
#!/bin/bash
# ====== CONFIGURATION ======
MANAGERS=("10.1.1.61" "10.1.1.62" "10.1.1.60")
MANAGER_USER="xxxxxx"
MANAGER_PASS="xxxxxx"
# Proxmox
PROXMOX_HOST="10.1.1.35"
PROXMOX_USER="xxxxxx"
PROXMOX_PASS="xxxxxx"
PROXMOX_VM_ID=109
# New Node (standby VM details)
NEW_NODE_IP="10.1.1.63"
NEW_NODE_HOSTNAME="new-manager-node"
NEW_NODE_USER="xxxxxx"
NEW_NODE_PASS="xxxxxx"
SWARM_JOIN_CMD="docker swarm join --token SWMTKN-1-xxxxx-xxxxx 10.1.1.62:2377"
# ====== FUNCTION TO CHECK IF A NODE IS UP ======
check_node_up() {
curl -s --connect-timeout 3 http://$1:9100/metrics > /dev/null
return $?
}
# ====== CHECK ALL MANAGERS ======
echo " Checking Swarm manager nodes..."
any_down=false
for ip in "${MANAGERS[@]}"; do
if check_node_up "$ip"; then
echo "✅ Manager $ip is UP"
else
echo "❌ Manager $ip is DOWN"
any_down=true
fi
done
# ====== IF ALL MANAGERS ARE UP, EXIT ======
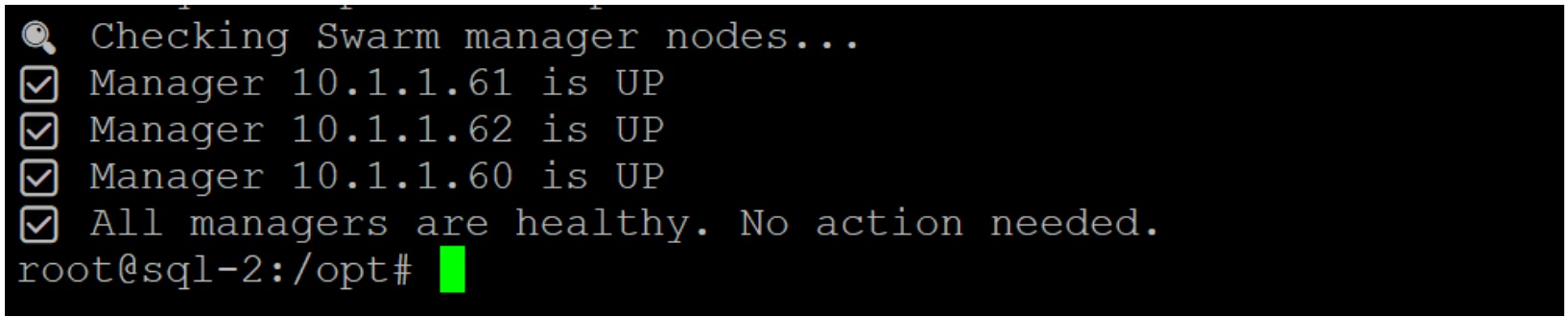
if ! $any_down; then
echo " All managers are healthy. No action needed."
exit 0
fi
# ====== START STANDBY VM FROM PROXMOX ======
echo " Starting VM $PROXMOX_VM_ID via Proxmox ($PROXMOX_HOST)..."
sshpass -p "$PROXMOX_PASS" ssh -o StrictHostKeyChecking=no ${PROXMOX_USER}@${PROXMOX_HOST} "qm start ${PROXMOX_VM_ID}"
echo " Waiting for ${NEW_NODE_IP} to be reachable via SSH..."
until nc -z ${NEW_NODE_IP} 22; do
echo " ... still waiting ..."
sleep 5
done
echo " VM ${NEW_NODE_IP} is online."
echo " Waiting 30 seconds for the new VM ($NEW_NODE_IP) to boot..."
sleep 30
# ====== JOIN THE NEW NODE TO THE SWARM ======
sshpass -p "$NEW_NODE_PASS" ssh -tt -o StrictHostKeyChecking=no ${NEW_NODE_USER}@${NEW_NODE_IP} "echo $NEW_NODE_PASS | sudo -S ${SWARM_JOIN_CMD}"
# ====== PROMOTE THE NEW NODE TO MANAGER ======
for manager_ip in "${MANAGERS[@]}"; do
if check_node_up "$manager_ip"; then
echo " Promoting $NEW_NODE_HOSTNAME to manager from $manager_ip..."
sshpass -p "$MANAGER_PASS" ssh -o StrictHostKeyChecking=no ${MANAGER_USER}@${manager_ip} "echo $MANAGER_PASS | sudo -S docker node promote $NEW_NODE_HOSTNAME"
break
fi
done
echo " Swarm repair completed."Key Logic:
- curl is used to check the /metrics endpoint of each node.
- If a node responds, it is marked as healthy.
- If a node fails the health check, the script triggers the standby VM startup and joins the node to the Swarm.
Script output during all master nodes up
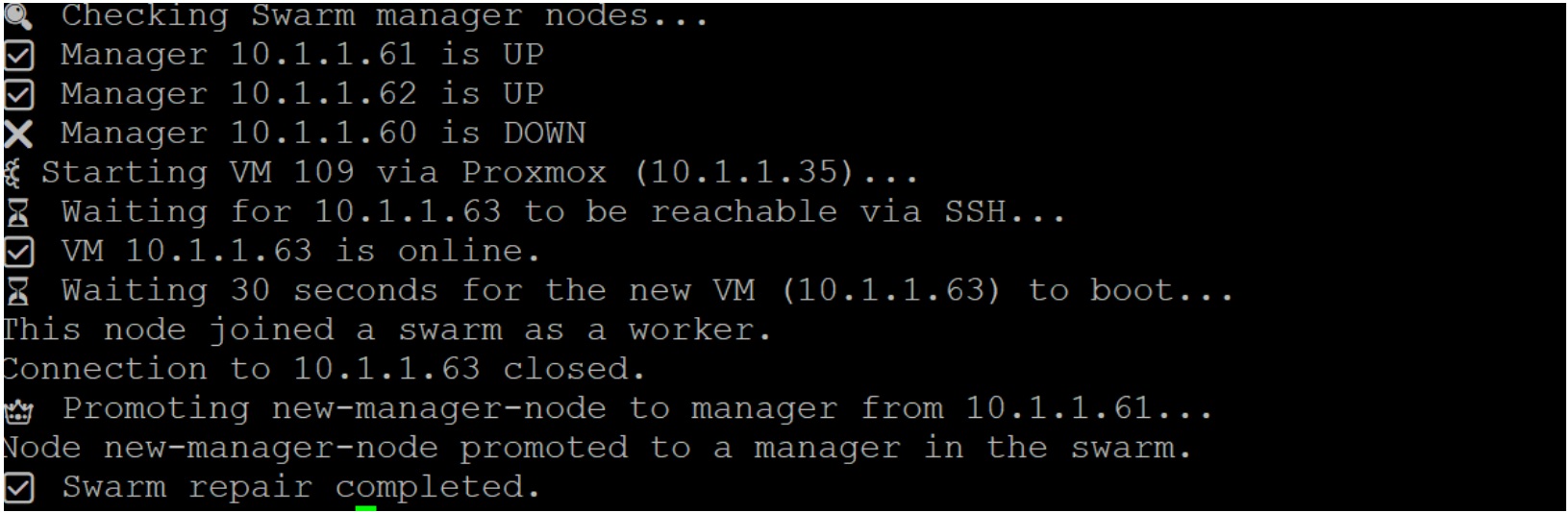
Script output during one node failure
If any Swarm manager node is detected as down, the monitoring script initiates a recovery process. It first connects to the Proxmox host via SSH and starts the standby VM (VM 109) using the qm start command. The script then continuously checks if the standby VM is reachable on port 22 (SSH), and once accessible, it waits an additional 30 seconds to ensure the system has fully booted. After the standby VM is ready, the script SSHs into it and executes the docker swarm join command to add it to the cluster as a worker node. Finally, the script connects via SSH to any healthy existing manager node and runs the docker node promote command to promote the standby node to a Swarm manager, thereby restoring cluster quorum automatically.

Summary of Benefit
- Ensures Swarm manager quorum is maintained even if a node fails.
- Automated recovery without manual intervention.
- Rapid fault detection and VM restoration.
Note: Similar to the high availability (HA) setup for Docker master nodes, we can also scale the worker nodes dynamically. By monitoring CPU and memory utilization metrics using Prometheus, additional worker nodes can be automatically added to the Docker Swarm cluster when resource usage exceeds a defined threshold (e.g., 75%).